")
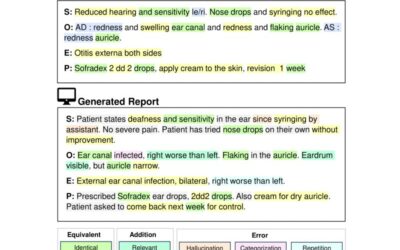
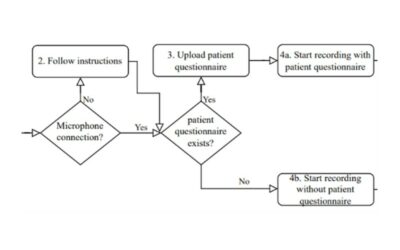
Automated Speech Recognition software is implemented in different fields. One of them is healthcare in which it can be used for automated medical reporting, the field of focus of this research. For the first step of automated medical reporting, audio files of consultations need to be transcribed. This research contributes to the investigation of the optimization of the generated transcriptions, focusing on categorizing audio files on specific characteristics before analyzing them. The literature research within this study shows that specific elements of speech signals and audio, such as accent, voice frequency and noise, can have influence on the quality of a transcription an Automated Speech Recognition system carries out. By analyzing existing medical audio data and conducting a pilot experiment, the influence of those elements is established. This is done by calculating the Word Error Rate of the transcriptions, a useful percentage that shows the accuracy. Results of the analysis of the existing data show that noise is an element that carries out significant differences. However
the data of the experiment did not show significant differences. This was mainly due to having not enough participants to reason with significance. Further research into the effect of noise, language and different Automated Speech Recognition technologies should be done based on the outcomes of this research.
DOWNLOAD THE PUBLICATION HERE IN PDF:
![]()